La partie antérieure a mis en évidence la nécessité d'identifier un modèle sous-jacent à toute formule d'allocation, reposant sur ce que la connaissance croît savoir de l'utilisation effective et normative des services de santé à un moment donné du temps. Les indices doivent donc reposer sur une modélisation préalable des relations complexes entre facteurs sociaux- mortalité - morbidité - offre - utilisation des services . Dans un premier temps, la méthode explicitera le modèle considéré ici, avant de décrire les variables accessibles et les outils statistiques mobilisés .
Le développement d'une formule complexe d'allocation prospective locale des ressources se justifie lorsque au moins trois conditions sont remplies :
Nous traiterons plus spécifiquement les premier et deuxième points et considérons que la troisième condition est d'autant plus satisfaite que la prévention se développe de plus en plus dans le cadre d'une approche communautaire(39,41) .
Il est donc nécessaire, dans un premier temps, de mesurer l'importance de la dimension spatiale des phénomènes de mortalité, morbidité et facteurs sociaux de manière à classer ces derniers par ordre d'importance en termes d'ancrage spatial : plus une cause de mortalité est spatialement spécifique, plus elle requiert une allocation locale en ce qui la concerne, sous réserve de la deuxième condition mentionnée ci-dessus . Dans un premier temps, ce travail effectuera donc une mesure de la corrélation spatiale des diverses causes de mortalité, de morbidité et de facteurs sociaux .
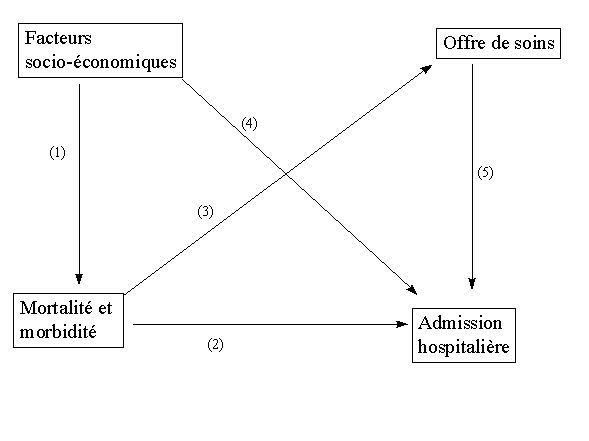
Figure 2. Modèle d'utilisation des services de santé.
L'estimation des coefficients de Moran est également une étape nécessaire à l'étude des facteurs sociaux : en effet, l'autocorrélation spatiale a pour effet d'induire une autocorrélation des erreurs lorsqu'une analyse multivariée est réalisée à un niveau géographique agrégé , ce qui, à son tour, provoque, une sur-estimation (en cas d'autocorrélation positive) de la précision des estimateurs(95) . Ne pas tenir compte de l'autocorrélation spatiale lors d'une analyse multivariée, par exemple du chômage sur le taux de mortalité standardisé toutes causes, revient à omettre la redondance de l'information d'une commune à l'autre, et donc à surestimer le degré de liberté : on fait comme si on avait 589 observations indépendantes, alors qu'elles sont structurellement dépendantes. Il n'est en effet pas correct de supposer que le chômage de Philipeville est indépendant de celui de Florennes.
La construction de la formule d'allocation fait appel à un modèle d'utilisation des ressources . Sur base des travaux britanniques(13,29), le modèle de la Figure 2 est proposé . Il suppose plusieurs relations :
Nous n'avons pas pu considérer des variables incluses dans les mécanismes d'allocation comme le coût de la prise en charge des diverses pathologies considérées . Dans le domaine qui nous concerne, la prévention, nous ne disposons pas de données belges sur le coût unitaire de services préventifs par rapport à des pathologies comme le cancer du poumon, le cancer du sein, les affections ischémiques, la cirrhose du foie , etc. Ce travail implique donc une hypothèse de coût unitaire égal des services.
La mesure du modèle est réalisé sur base de l'ensemble des 589 communes de fusion de la Belgique. Dans une phase ultérieure, les grandes agglomérations pourraient être éclatées en des sous-ensembles plus homogènes. Afin de prendre en ligne de compte, dans la modélisation, d'effets propres au nord et au sud, des variables dummy seront généralement introduites. Les formules d'allocation, quant à elles, ne s'adressent qu'à la Communauté française de Belgique puisque l'allocation envisagée concerne une compétence communautaire.
L'opérationalisation de ce modèle repose sur plusieurs étapes :
L'élaboration des formules, à partir de ce modèle, est discutée plus bas (*).
Les données
- Toutes les variables traitées dans ce travail sont produites au niveau d'agrégation communal (commune de fusion INS) correspondant à 589 communes . Les données de mortalité ne furent disponibles que pour les 557 communes dans lesquelles au moins 30 décès sont enregistrés par an. La prévalence de surcharge pondérale ne fut calculée que pour les communes comptant avec au moins 100 miliciens entre 1980 et 1990, soit 549 communes.
Les variables de besoins de santé
- Plusieurs variables de santé ont été utilisées en tenant compte de notre champ spécifique (prévention primaire et secondaire) et de la disponibilité d'informations au niveau communal.
La mortalité vulnérable à de la prévention .
- La mortalité vulnérable est entendue ici par les taux de mortalité et de morbidité standardisés (voir SMR page *) sur neuf ans pour les affections vulnérables à de la prévention primaire et secondaire . La liste des codes (voir Tableau 5 ) a été choisie en considérant les causes de mortalité sensibles à de la prévention primaire ou secondaire, dans le cadre de la médecine préventive(105) ou de l'éducation à la santé(27) . La période couverte va de 1985 à 1993 et fut étudiée par groupes de trois ans (1985-1987, 1988-1990, 1991-1993)
Tableau 5. Codes ICD9 pour le calcul des SMR.
- La mortalité toutes causes a été également calculée pour tous les âges (SMRTot) et pour les âges inférieurs à 65 ans (SMR_64), appelée par la suite mortalité prématurée.
La surcharge pondérale.
- L'obésité est considérée comme un facteur de risque majeur des affections coronariennes(62,93) et, à ce titre, comme un des objectifs prioritaires en matière de santé dans plusieurs systèmes de pilotage de la santé publique : Healthy People 2000 aux USA (Objectifs 2.3 et 15.10), Health of the Nation du Royaume-Uni, Health For All (Objectif 16) .
L'indicateur qui sera utilisé ici est la prévalence de personnes affectées de surcharge pondérale, soit la proportion d'individus connaissant un index BMI >= 25., le BMI étant un indicateur de masse corporelle équivalent à Poids (en Kg) / taille (en m)2 . Le seuil de 25, outre qu'il est très couramment utilisé, correspond également au risque minimal de mortalité(33) dans une population blanche nord-américaine . La surcharge pondérale est estimée à partir des données du Centre de Recrutement et Sélection (CRS) des Forces Armées Belges, rassemblant annuellement quelque 48.000 hommes dans la tranche d'âge 16-30 à l'occasion de leur comparution au CRS . Etant donné le faible nombre de cas de jeunes de 16 et 17, nous avons restreint l'analyse au groupe d'âge 18-30 et aux années 1979 à 1990, par moyenne sur trois ans : 1979-1981,1982-1984,1985-87,1988-1990.
Le choix de la surcharge pondérale (BMI>=25) plutôt que l'obésité (BMI >=30) se justifie par deux raisons: d'une part la faible prévalence d'obésité dans notre groupe d'âges (18-30; voir tableau ) avec les risques d'inflation de variance en pareille situation et d'autre part, par rapport à une préoccupation de comparaison avec les résultats de Healthy People 2000 qui utilise la surcharge pondérale plutôt que l'obésité(83) .
Le tableau suivant présente les prévalences de surcharge pondérale, mettant en évidence une augmentation de 5% au cours des années 80.
Tableau 6. Prévalence de surcharge pondérale chez les jeunes comparaissant au CRS.
Période Proportion de BMI >=25 Nbre de communes Nbre total de comparutions 1979-1981
0.161
569
148775
1982-1984
0.161
570
147342
1985-1987
0.185
570
137489
1988-1990
0.211
565
129274
L'incidence du cancer
Les données du Registre National du Cancer ont été exploitées afin d'estimer des taux standardisés d'incidence du cancer pour le poumon, le sein, le colon/rectum et l'utérus . Le cancer de la prostate n'a pas été retenu en dépit de son importance relative (c'est le deuxième localisation la plus fréquente chez l'homme avec 18% en 1994), car aucun facteur de risque exogène n'a été mis en évidence et que son dépistage systématique n'est pas recommandé(105) . Il en est de même pour le cancer des ovaires chez la femme.
Tableau 7. Incidence de cancers vulnérables par site (codes ICD7) .
|
|
|
|
|
||
|
|
Homme |
Femme |
|
|
|
|
Poumon |
25% |
5% |
162-163 |
40438 |
|
|
Côlon-Rectum |
13% |
14% |
153-154 |
29648 |
|
|
Utérus |
|
4% |
171 172 173 174 |
10604 |
|
|
Sein |
|
34% |
170 |
40685 |
|
*Données d'incidence . Source : Registre National du Cancer 1994
On trouvera dans INFOSANTE, une discussion sur les indicateurs et leurs propriétés. Les deux précautions principales qui y sont mentionnées sont liées au mécanisme d'enregistrement des cancers via les Organismes Assureurs :
L'évaluation du Registre National du Cancer (RNC) a été réalisée sur base de quelques critères du "International Agency for Research on Cancer" : comparaison entre incidence et mortalité, comparaison des taux d'incidence standardisés par âge avec les taux provenant d'autres registres, pourcentage de cas ayant obtenu un diagnostic confirmé par voie anatomopathologique . En ce qui concerne le Registre national du Cancer belge, le ratio entre incidence/mortalité est de 1,06 chez les hommes et 1.43 pour les femmes; cela reflète un certain degré de sous-estimation des cancers du sexe masculin(44) . La comparaison avec les taux d'incidence dans d'autres pays européens , sous l'hypothèse d'une exposition égale, semble confirmer ce dernier diagnostic.
En ce qui concerne la proportion de cas confirmés par examen anatomopathologique, il oscille autour de 80%. Afin de vérifier la concordance entre les données d'incidence et celles de mortalité, nous avons calculé le nombre de cas et de décès par cancer du poumon (hautement létal) pour deux périodes pour lesquelles nous disposions de données tant du RNC que de l'INS. La médiane de survie du cancer du poumon étant proche de 12 mois, le nombre total de décès et le nombre total de cas sur une période de 3 ans devraient être très proches. Cela n'est pas le cas. Une différence significative de 20% est observée pour chaque période .
Tableau 8. Incidence et mortalité par cancer du poumon, tous sexes et âges.
|
Période |
|
(INS) |
|
|
1988-1990 |
15320 |
19125 |
20% |
|
1991-1993 |
15032 |
19564 |
23% |
La standardisation des taux d'incidence s'est réalisée de la même manière que pour la mortalité.
Les variables d'utilisation des services : l'admission hospitalière.
L'utilisation des services de santé est indispensable à l'élaboration de toute formule . Le modèle présenté dans la Figure 1, page * fut élaboré pour l'allocation des ressources hospitalières, tandis que le champ qui nous occupe ici est celui de la promotion de la santé . Idéalement, nous devrions disposer de données sur l'utilisation des services de promotion de la santé et non pas de l'utilisation du seul système curatif hospitalier . Le problème est, qui plus est, compliqué par l'antériorité des services de promotion de la santé par rapport aux besoins de santé mesurés par la mortalité et la morbidité. En effet, si les services de promotion de la santé sont utilisés, les besoins d'hospitalisation devraient diminuer ou se reporter sur les âges; tandis que la planification dans le secteur des soins de santé peut légitimement supposer une relation positive entre besoin (mortalité-morbidité) et utilisation des services , cette relation devient théoriquement négative en ce qui concerne la promotion de la santé . Trois raisons justifient toutefois la validité de cette variable :
L'hospitalisation présente toutefois plusieurs défauts lorsqu'elle est utilisée à des fins d'analyse des besoins : elle est influencée par l'accessibilité et les pratiques d'hospitalisation, à morbidité donnée. Il est donc nécessaire de tenir compte, simultanément, des variables d'offre .
L'indicateur relatif à l'hospitalisation est le taux standardisé d'admission hospitalière selon le domicile des patients pour la période 1989-1993. La standardisation est, ici, directe et ne porte que sur trois groupes d'âges (0-14; 15-64; 65 et+) .
Tableau 9. Admission hospitalière : 1989-1992.
|
Groupe d'âges |
Taux d'admission hospitalière |
|
0-14 ans |
0.11 |
|
15-64 ans |
0.13 |
|
65 et plus |
0.44 |
L'offre
- Deux variables relatives à l'offre de service seront utilisées ici :
La densité de médecins généralistes et de médecins spécialistes pour 10.000 ha (équivalent temps plein) est établie par commune en fonction de l'activité totale de ces derniers. Les données sont tirées de la base de données PERSMED (UCL-SESA) pour les années 1989-1991.
La troisième révision des RAWPS a également utilisé une mesure d'accessibilité fondée sur l'origine des admissions-patients des hôpitaux(17) . Nous ne disposons pas de ce genre de données .
Les facteurs socio-économiques. .
Le choix des indicateurs socio-économiques à considérer dans notre modèle est la résultante de trois préoccupations : validité théorique, non-redondance et accessibilité . Le tableau synthétise les indicateurs utilisés .
Tableau 10. Les indicateurs socio-économiques.
|
Indicateur |
Validité théorique |
Source et Période |
Construction |
Moyenne (STD) |
|
|
|
|
|
|
|
Revenu |
(6,116) |
INS, 1981-1989 |
Revenu médian en francs constants de 1981, moyenne sur trois ans. |
384,04 (34,45) * |
|
Concentration du revenu |
(6,59,106,114) |
INS, 1915-1989 |
Coefficient de gini, soit la différence moyenne de revenu entre deux individus tirés au hasard, en % du revenu moyen. |
0,330 (0,059) |
|
Chômage |
(20,34,108) |
INS, 1980-1989 Recensement 91 |
Nombre de chômeurs complets indemnisés / population en âge de travailler . |
0,11 (0,05) |
|
Niveau d'étude |
(6,68,72) |
Recensement 91 |
Personnes ayant comme diplôme le plus élevé celui de l'enseignement primaire / personnes ne suivant plus d'enseignement de plein exercice . |
0,24 (0,052) |
|
Enseignement professionnel |
(91) |
Recensement 91 |
Nbre de jeunes inscrits dans l'enseignement secondaire professionnel en rapport au nombre de jeunes suivant un enseignement secondaire quelconque . |
0,21 (0,05) |
|
Catégorie d'occupation |
(52,68) |
Recensement 91 |
Proportion d'ouvriers en rapport à la population active travaillant. |
0,33 (0,09) |
|
Ménage monoparental |
(85-87) |
Recensement 91 |
Proportion de ménage monoparental avec enfants de moins de 16 ans |
0,028 (0,011) |
|
Isolement |
(81) |
Recensement 91 |
Nombre de personnes âgées (65 ans et +) vivant seules par rapport à la population de 65 ans et +. |
0,28 (0,05) |
|
Salubrité du logement |
(13,18) |
Recensement 91 |
Proportion d'habitations avec eau courante à l'intérieure du logement. |
0,92 (0,07) |
|
Salubrité du logement |
(13,18) |
Recensement 91 |
Proportion d'habitations avec WC privé |
0,879 (0,073) |
|
Confort du logement |
(13,18) |
Recensement 91 |
Proportion d'habitations sans chauffage central individuel ou commun |
0,39 (0,124) |
|
Confort du logement |
(13,18) |
Recensement 91 |
Proportion d'habitations sans salle de bain ou douche. |
0,115 (0,049) |
|
Exiguïté du logement |
(13,18) |
Recensement 91 |
Moyenne de la surface habitable par personne de plus d'1 an (question 11 b/ nbre de personnes de plus d'1 an). |
40,1 (2,69) |
|
Equipement |
(13,18) |
Recensement 91 |
Proportion de ménage sans voiture . |
0,262 (0,063) |
|
Minorité ethnique à risque |
(13) |
Recensement 91 |
Proportion d’habitants dont la nationalité à la naissance était turque ou marocaine |
0,021 (0,026) |
* en 1000 BEF de 1981 .
Les outils statistiques
La standardisation
- Le taux de mortalité dans la commune i est mesuré par un taux standardisé de manière indirecte, soit le ratio entre un nombre de décès observés (O) et un nombre de décès attendus (A); ce dernier est la somme du produit d'une distribution nationale de la mortalité par classe d'âge (soit la séquence des 20 TXg de la période 1988-1990) et de la population communale dans chaque groupe d'âge (soit les Pgi)
Equation 1. Intervalle de confiance d'un SMR pour O suivant une loi normale.
- Le choix de la standardisation indirecte se justifie par deux raisons : d'une part les contraintes sur la confidentialité des données ne permettent un accès, au niveau communal, qu'à des totaux de décès observés sans ventilation par classe d'âges. Par ailleurs, le SMR dispose de propriétés satisfaisantes(11) lorsque les populations ne sont pas trop hétérogènes les unes des autres . Il a également l'avantage d'une plus grande précision que la standardisation directe lorsque le nombre de cas est faible .
L'intervalle de confiance d'un SMR ou SIR est donné par la formule suivante lorsque O est supposé suivre une loi normale .
Toutefois, le faible nombre de cas par commune, rend précaire l'hypothèse de normalité et il est dès lors préférable de supposer que le nombre O suit une loi de Poisson avec un intervalle de confiance (CI) à 95% proposé par Kahn et Sempos (55) . Remarquons que, dans les deux cas, l'absence d'erreur d'échantillonnage sur A est supposée acquise .
Equation 2. Intervalle de confiance d'un SMR pour O suivant une loi de Poisson.
L'intervalle du SMR dépend donc fortement du nombre de décès et le nombre de décès nécessaires pour mettre en évidence des différences d'une commune à l'autre décroît exponentiellement avec la différence en % (voir Figure 3).
Figure 3. Nombre de décès et surmortalité.
Il faut toutefois noter que cette procédure de standardisation n'effectue un ajustement que pour la partie linéaire de la relation mortalité-âge. Elle suppose en effet que l'âge et le sexe jouent sur la mortalité de manière uniforme sur l'ensemble du territoire belge, ce qui est quelque peu arbitraire. Il est en effet aisé de supposer que la mortalité soit conditionnée de manière non-linéaire à l'âge : par exemple si le taux de mortalité dans la classe d'âge 65-69 varie en relation avec l'appartenance géographique, de sorte que l'effet de l'âge sur la mortalité soit du type a + b*region . Ceci explique que même après standardisation indirecte, il reste une certaine corrélation entre le taux de mortalité et la distribution de la population par classe d'âges .
L'autocorrélation spatiale
- Il existe diverses statistiques d'autocorrélation spatiale, tels que le I de Moran, le C de Gary et le D des rangs adjacents . Le I de Moran a été choisi, car il présente une puissance plus élevée(112) . L'autocorrélation spatiale est donc mesurée ici de la manière suivante(58) :
Xi et Xj sont les log des SMR des entités géographiques i et j respectivement ;
est la moyenne des log SMR ;
Wij vaut 1 si i et j sont contigus, 0 autrement;
n est le nombre d'entités géographiques .
Sous l'hypothèse nulle d'absence d'autocorrélation spatiale, l'espérance mathématique et la variance de I sont estimées , respectivement de la manière suivante (22):
Aux conditions que les Xi soient distribués selon une loi normale d'espérance m et de variance s 2, , E(Zi,Zj) vaut -s 2/n . et
Le coefficient I peut être testé par le test I-E(I) / Var(I)0.5 qui suit une loi normale N(0,1) . I oscille entre -1 et 1 et s'interprète comme un coefficient de corrélation de Pearson . Il vaut -1 en cas d'autocorrélation spatiale parfaitement négative : en ce cas, des zones à haute mortalité sont voisines de zones à faible mortalité ; il s'approche de 1 en cas de corrélation positive , c'est-à-dire lorsque des zones à haute mortalité sont contiguës de zones à haute mortalité également . En l'absence d'autocorrélation, I s'approche de -1/(n-1).
Il faut toutefois noter qu'un problème d'hétéroscédascticité peut se présenter(110,111). En effet, la variance de l'estimateur (par exemple d'un SMR) n'est sans doute pas constante d'une entité géographique à l'autre et est vraisemblablement plus élevée dans les zones à faible densité . Cela est d'autant plus vrai pour un SMR dont la variance est directement proportionnelle au nombre de décès (voir Equation 1, page *) . Etant donné que les zones à faible densité sont également souvent contiguës, il est possible qu'une partie de l'autocorrélation observée des SMR soit imputable à la plus gande variance des SMR dans ces zones que dans les zones à densité plus importante(24). L'omission de l'hétérogénéité de la densité génère une augmentation de l'erreur de type I , principalement pour les statistiques C de Gary et le D : de5% à 23% dans le premier cas et de 5% à 9% dans le deuxième cas(111). Pareille inflation de l'erreur de type I ne semble pas se produire en ce qui concerne le I de Moran . Waldhör a proposé d'estimer la covariance entre deux entités par la formulation suivante :
Cela revient a intégrer dans le calcul de l'espérance mathématique des covariances d'autant grandes pour deux entités géographiques contiguës et de faibles densités . Enfin, il faut ajouter que les SMR étant un ratio, ils ont été pris en base logarithmique, ce qui, par ailleurs, rend les estimateurs de Moran plus robustes . Une alternative consisterait à utiliser le rang du SMR .
Procédures d'estimation
Le modèle (Figure 2 ) ne peut pas être estimé par un moindre carré ordinaire (MCO). D'une part, on se trouve face à un système d'équations simultanées dans lequel , par exemple, la mortalité est à la fois variable explicative de l'hospitalisation et dépendante des facteurs sociaux . Par ailleurs, les variables sont toutes affectées d'autocorrélation spatiale ce qui provoquerait une sur-estimation de la précision des estimateurs (dans le cas d'autocorrélation positive) via un MCO . Les modèles autorégressifs simultanés s'efforcent de purger des Y (variables dépendantes ) et X (variables indépendantes) l'autocorrélation spatiale en considérant toute observation comme étant une combinaison linéaire des observations contiguës (matrice de contiguïté Wij) sous la forme
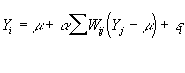
de telle sorte que l'investigation de la relation entre Y (par exemple la mortalité toutes causes) et les facteurs sociaux (chômage, revenu, niveau d'instruction, etc.) est testée de la manière suivante :
![]()
c'est-à-dire que la mortalité est décomposée en :
Concrètement, la mesure de la corrélation ainsi que les procédures de régression sont opérées sur des variables purgées de leur autocorrélation spatiale . Cela se réalise en étapes :
Les formules d'allocation.
L'allocation peut être envisagée à divers niveaux d'agrégation géographique : province, arrondissement. Le décret de la promotion de la santé (39) est explicite sur le nombre de Centres Locaux de Promotion de la Santé auxquels échoient une mission de coordination locale des actions en promotion de la santé. Il est donc apparu pragmatique de considérer ce niveau de regroupement géographique.
A partir des résultats du modèle plusieurs formules peuvent être élaborées selon les objectifs à atteindre :
La première formule est fondée sur les déterminants "légitimes" de l'utilisation des ressources, soit les variables de santé (directement et via l'offre) et les facteurs sociaux . Dans ce cadre, une zone géographique disposera des ressources unitaires d'autant plus grandes que le niveau socio-économique est bas et que la mortalité est élevée .
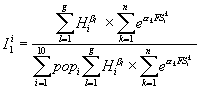
Equation 3. Formule d'ALR fondée sur la relation à l'utilisation des ressources .
L'indice relatif de besoin de l'arrondissement i est le rapport entre l'indice de besoin de l'arrondissement i (soit le numérateur de Equation 3) et l'indice global de besoins tous arrondissements confondus (dénominateur) . Le numérateur est le produit des indice de besoins de santé (soit les Hl, soit le taux de mortalité et la surcharge pondérale)et des facteurs socio-économiques (les FSk). Ces variables (H et FS) sont pondérées par le coefficient les reliant à l'utilisation des services (hospitalisation), respectivement les b et les a dans l'équation antérieure . Ces coefficients sont tirés des résultats LISREL du modèle de la Figure 2 sur les 589 communes belges . Les résultats sont présentés dans la Figure 5. Les coefficients b sont, pour chacune des variables de santé, la somme de l'effet direct (flèche 2 dans la Figure 2) de la mortalité sur l'utilisation des services et de l'effet indirect (flèche 3 * flèche 5) . Les coefficients a correspondent à la flèche 4 de la même figure. On pratique, le modèle intègre deux variables de santé (g=2) et trois facteurs socio-économiques (n=3) . Etant donné que les variables sont prises en base logarithme, les poids sont utilisés en exposant. Popi est le poids relatif de la population relevant de la CLPS i .
La formule antérieure repose sur l'hypothèse que l'hospitalisation et l'utilisation des services de promotion de la santé seraient positivement corrélés, hypothèse qui n'est pas vérifiée empiriquement . La deuxième formule est fondée sur les déterminants socio-économiques de la santé. Sur cette base, une zone géographique aura un besoin relatif d'autant plus élevé que le niveau des facteurs sociaux de la santé sont défavorables. Le poids des différents facteurs équivalent aux coefficients g de la flèche (1) de la Figure 2 . Cette formule a l'avantage de ce centrer sur les facteurs sociaux de la santé, en cohérence avec le plan quinquennal de la CFB(78); elle présente l'inconvénient d'ignorer la relation entre besoins et utilisation des ressources.
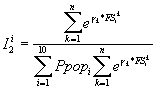
Equation 4. Formule d'ALR fondée sur les facteurs sociaux de la mortalité.
La troisième formule considère que les besoins relatifs sont directement et proportionnellement reliés à la mortalité : la relation entre utilisation des services préventifs et mortalité est donc supposée égal à 1.
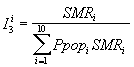
Equation 5. Formule d'ALR fondée sur la mortalité.
Les indices peuvent ensuite être utilisés afin de calculer des parts dans un budget total donné en multipliant chaque indice par la population de l'arrondissement et en divisant par le total du produit .








